Are you still shocked about how many data projects are understaffed, poorly defined, or lack an overall cohesive strategy or purpose for the data? Because I work with data and maybe even more specifically in my role as a curator of data--I spend a lot of time listening. I listen to patients. Not little dots or circles described enthusiastically from the podium at JP Morgan Healthcare Conference as "expanding market share" but independent advocates, thoughtful executives, and physicians/healthcare providers at the point of care. I also made an observation. The closer the "expert" is to the patient, the more trustworthy they seem to be. Although I also work in health policy and health economics, the patient is way off in the distance. An ideal, rather than someone with an actual seat at the table. Business models swirl around each node in US health systems but we should not lose sight of the real objective--improving patient outcomes and prevention strategies upstream from disease. Why are we lamenting the closure of hospitals and condensed networks of health systems? Isn't that what success looks like if more and more people are healthy? 2018 is the first year in recent memory where I stepped away from the office during the entire holiday season. Okay maybe there were meetings here and there but mostly with clients that have become friends over the years. Projects have grown beyond the data itself and into the architecture driving governance strategies and frameworks. “Data”, runs a common refrain, “is the new oil.” Like the sticky black stuff that comes out of the ground, all those 1s and 0s are of little use until they are processed into something more valuable. That something is you. We see data everywhere and have discussions of objectivity and rigor in attempts to identify, clean, collect, analyze, and visualize. But what if we are identifying sources of information that support our prevailing beliefs and ideology? More than once, clients ask for the outcome without ever identifying the question they seek to answer. Are we doing the same thing? Even raw data has been selected and processed. An important quote by Nick Barrowman states that "data is always the product of cognitive, cultural, and institutional processes that determine what to collect and how to collect it." “Raw data” is both an oxymoron and a bad idea.—Geoffrey C. Bowker, Memory Practices in the Sciences Transparency in the selection of datasets, data models, and even the data you leave out because of budgetary limits should all be disclosed. My goal for 2019 is to encourage more collaborative partners to participate in the selection of entities, relationships, and attributes in building models. Knowing how we build the models expands the team knowledge of how questions should be articulated and considered. Paul Edwards defines “data friction” as—"friction consisting of worries, questions, and contests that assert or affirm what should count as data, or which data are good and which less reliable, or how big data sets need to be". I think about this a lot when analyzing oncology data. It is hard to compare multiple trials without noticing the broad selection and interpretation of surrogate endpoints, homogenized patient populations hardly representative of actual real world clinical environments, and the aggregation of data from disparate sets as representative of a single patient's "best" treatment algorithm. I recommend listening to Vinay Prasad MD MPH either by following on twitter or his recently launched podcast, Plenary Session. You may not be a data scientist but you do need to be able to read graphs and charts. You need to know when something stinks. Especially in oncology where we seem to suffer from a bit of dissonance. Why are we not able to accept failure in oncology clinical trials? Randomized controlled trials are conducted to minimize confounding. Not only measured confounders but those we aren't aware of. The group think is that variables will be evenly distributed across prognostic groups and minimize any impact. Vinay reminds us of this when he notes how p-hacking and negative studies exhaustively mined for anything positive--may actually introduce confounding we already mitigated by randomizing.
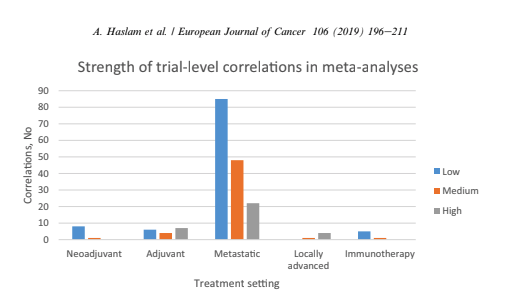
Vinay Prasad also has perfected the slow jam of tweet threads. One of the final of 2018 arrived with a ribbon on Christmas Eve 2018. This article was among the 15 most interesting things he read, listened or saw in 2018. The full paper is available on Google Drive, A systematic review of trial-level meta-analyses measuring the strength of association between surrogate end-points and overall survival in oncology. The graph below depicts the evolution of trial-level surrogates as evidence over the last ~ 18 years. 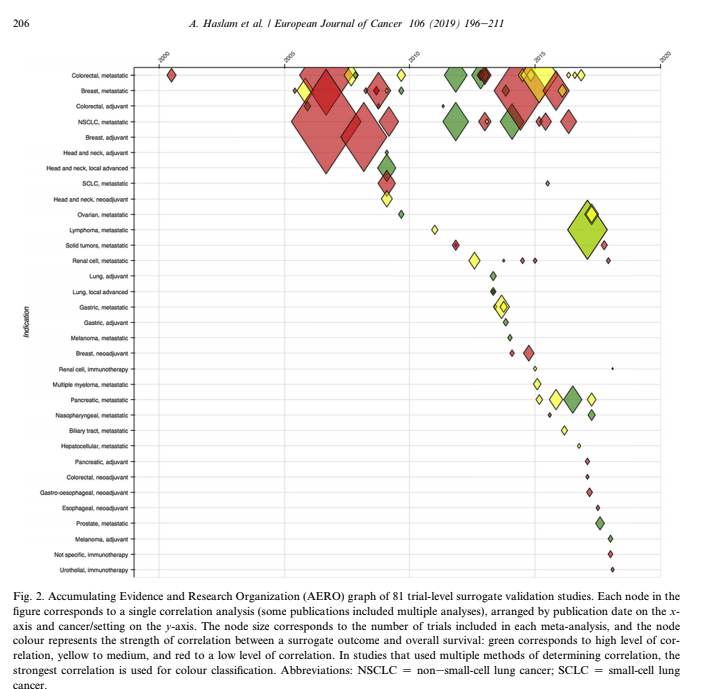 When reading clinical trial results or attending conference proceedings note the trend away from comparable and meaningful measures of proof and think about the data you need to see. What is meaningful in the clinical environment and what is a signal--barely detectable but audaciously hyped. The singular datum is not the particular in relation to any universal (the elected individual in representative democracy, for example) and the plural data is not universal, not generalizable from the singular; it is an aggregation. The power within aggregation is relational, based on potential connections: network, not hierarchy. Comments are closed.
|